
vol.3はグラフとしていったんできあがるまで
Tableauの初学者 of 初学者向けのシリーズ、今回はグラフとしていったんできあがるまでの手順を紹介します。
前回は「思ってたんと違う……」というものができあがってしまったところまででしたね。
ディメンションとメジャーの設定を変更する
ここでは詳しい解説は省きますが、Tableauにデータを接続した直後は自動的に「ディメンション」(区分やカテゴリを表す定性的な値のフィールド)と「メジャー」(集計ができる数値や定量的な値のフィールド)に振り分けられます。
今回は「週ごと」にデータを区分したいので、「週」は「ディメンション」であるべきなのですが、自動振り分けがうまくいっていなければユーザーが手動で修正します。
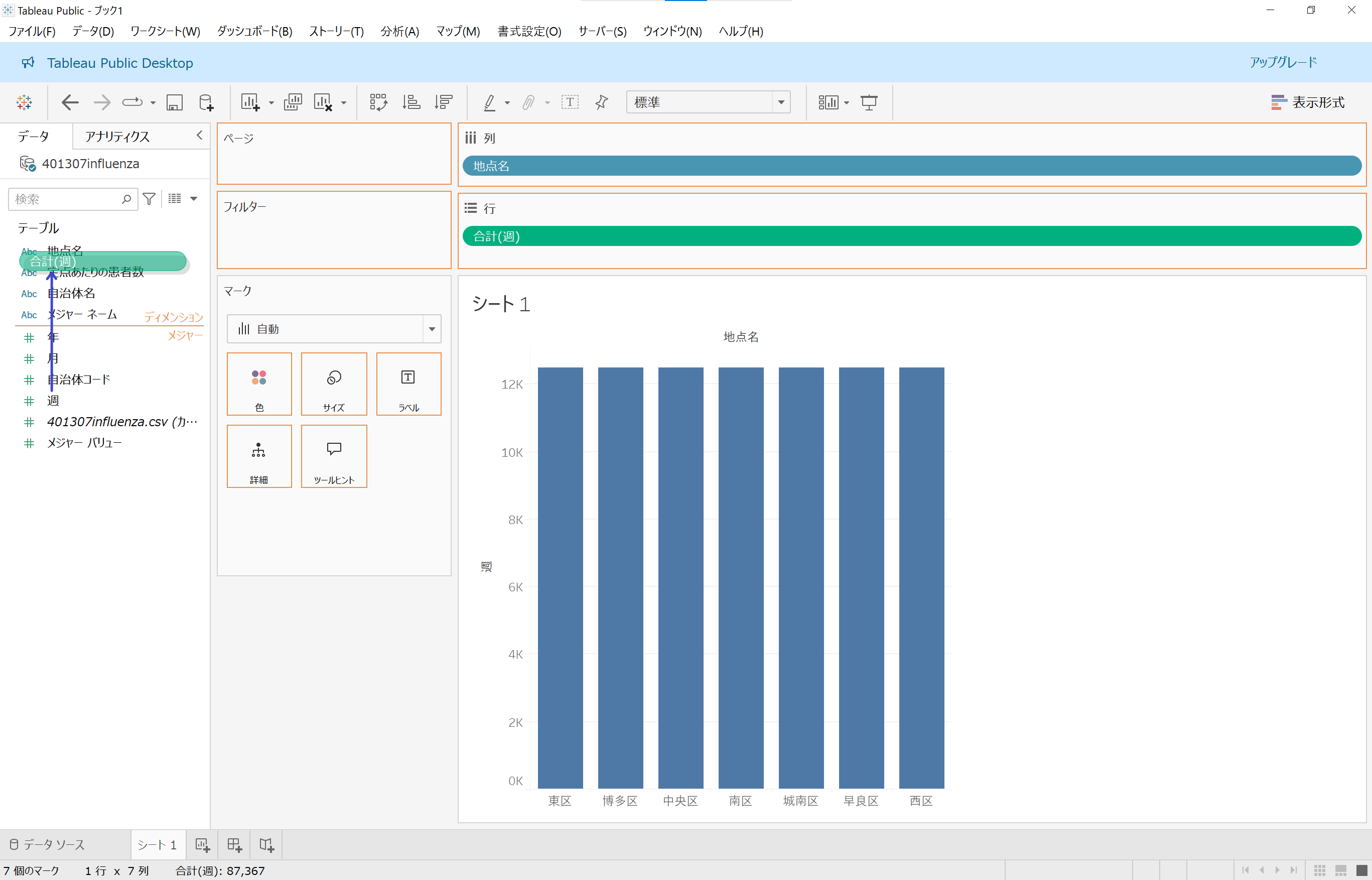
「週」フィールドを上の方にドラッグすると、「ディメンション」「メジャー」という境界を表す文字が表示されますので、「ディメンション」側にドロップします。
「週」フィールドがディメンションの方のエリアに配置されました。
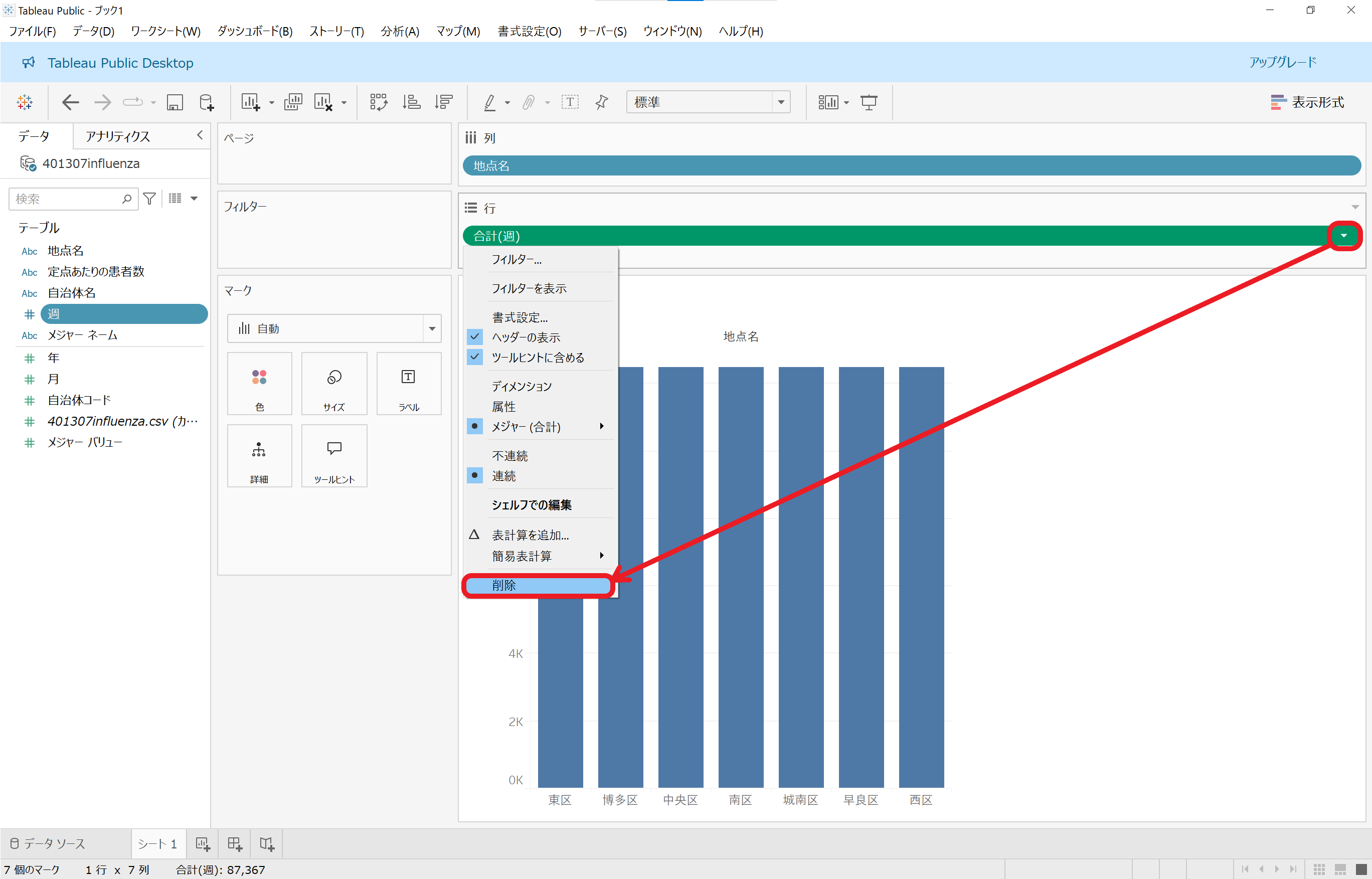
さっきの「思ってたんと違う」フィールドはいったん削除しましょう。「合計(週)」というラベルの右端の▽をクリックし、「削除」をクリックします。
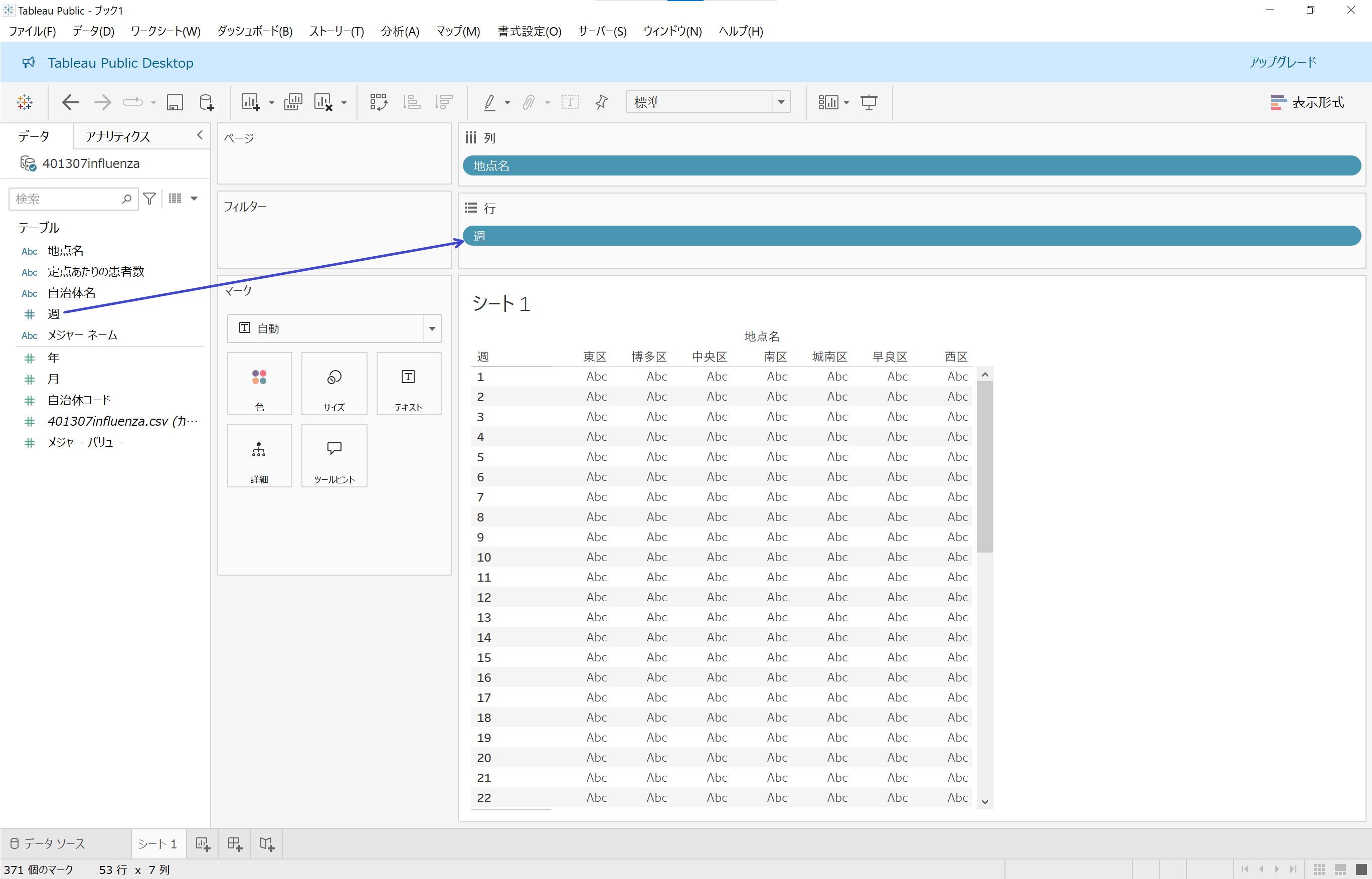
もう一度シェルフ内の「行」部分に「週」フィールドをドラッグ&ドロップします。
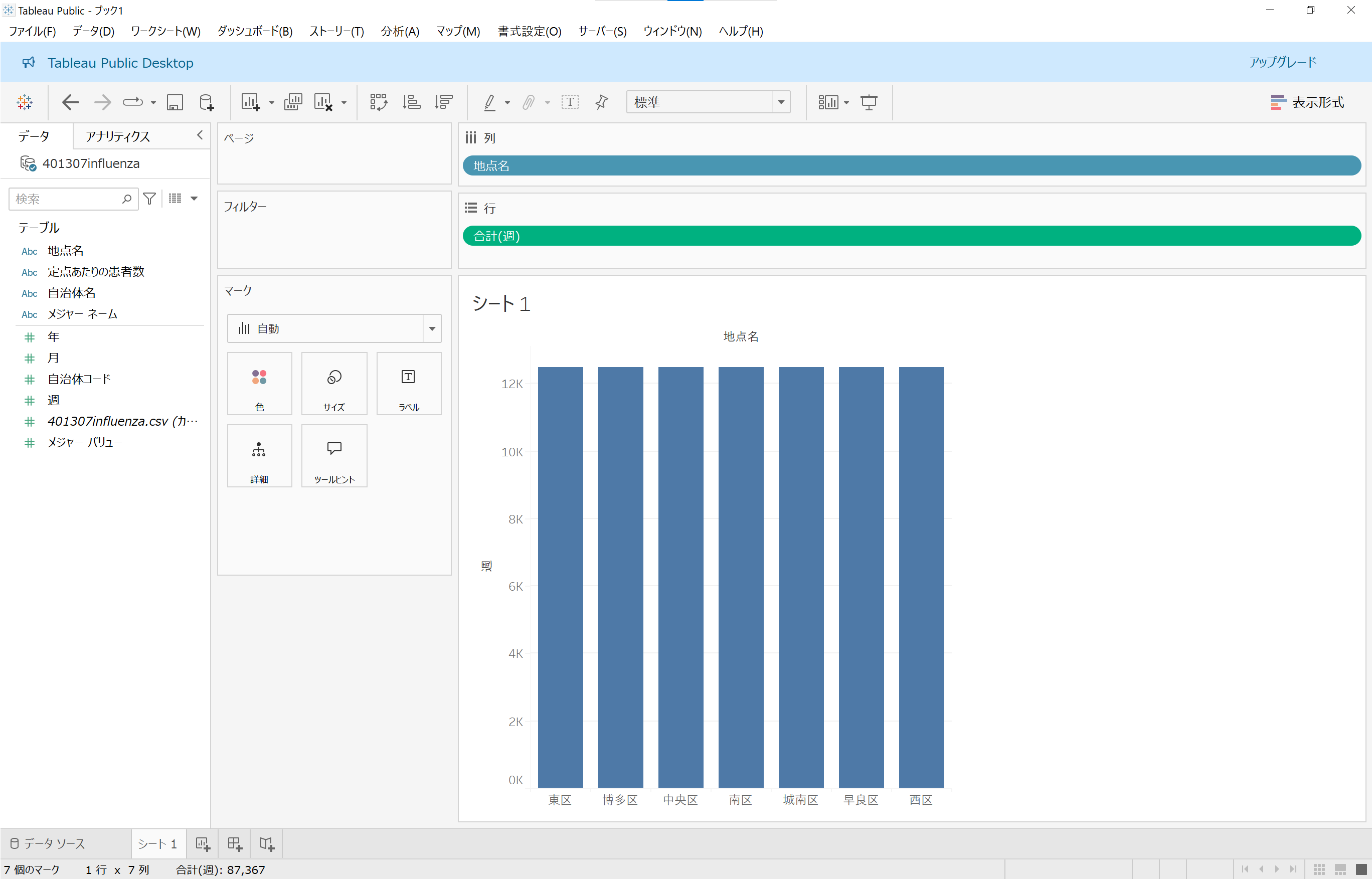
今度は週数ごとに行が、地点名ごとに列が設定されました!
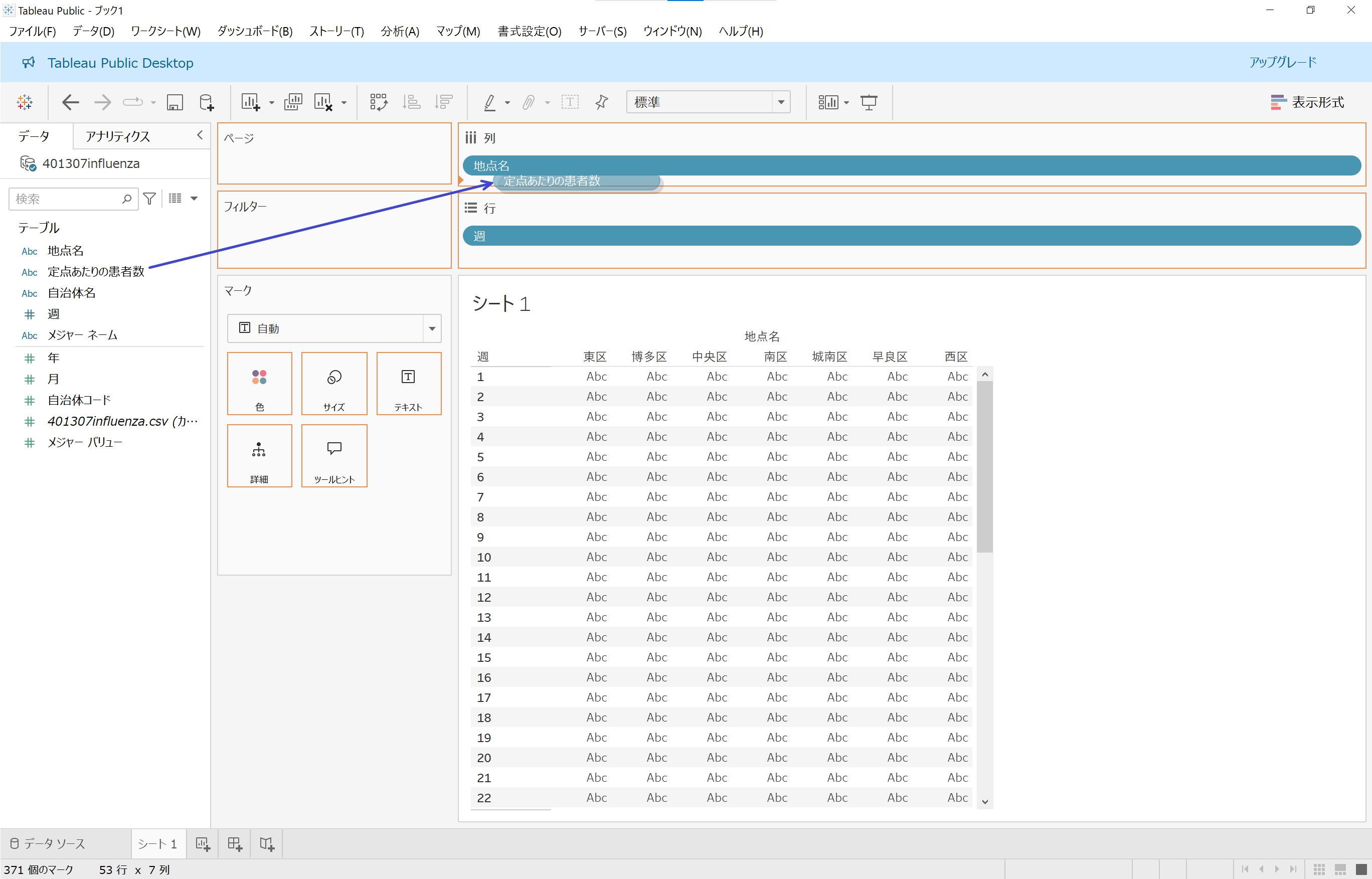
ガワがうまいことできたっぽいので、いよいよ数値を集計します。シェルフ内の「列」部分に「定点当たりの患者数」フィールドをドラッグ&ドロップします。
でも、「定点あたりの患者数」という「集計ができる数値や定量的な値」のはずなのに「ディメンション」側に居るので、なんかまた悪い予感がしてきたのう……
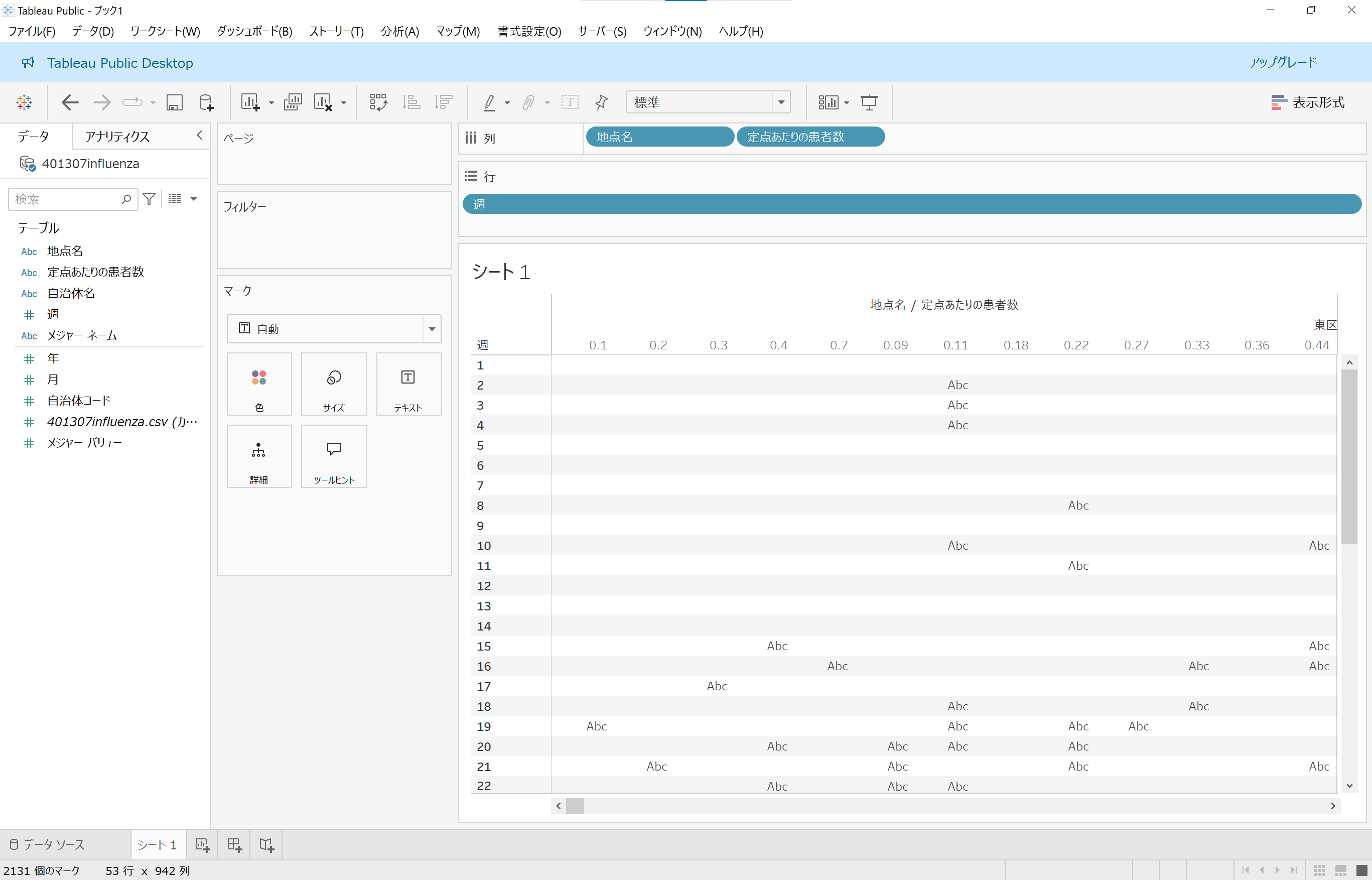
やっぱり「思ってたんと違う」感じになってしまいました。
そうそう、「列」「行」のシェルフに配置されたフィールドがやたら横長くなってしまっているので、シェルフの高さをマウスでドラッグして狭くしましょう。
この図のような高さに設定すると、フィールド名が横に長くなりすぎずに表示されるようになります。
表示を調整したので、手順に戻ります。
せっかくなので、今度は「シェルフから削除」ではない対処方法を紹介します。
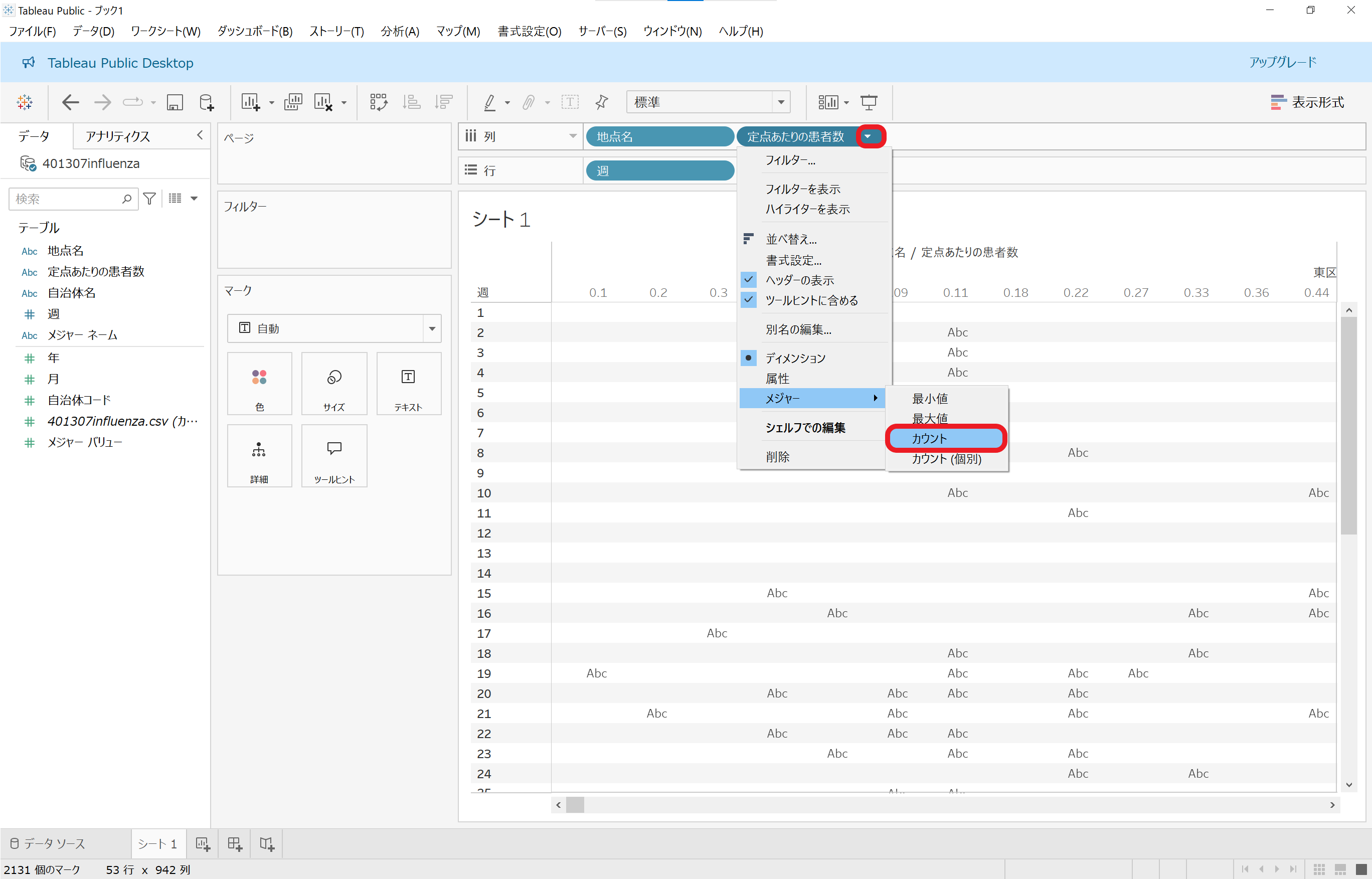
「定点あたりの患者数」のラベルの右端の▽をクリックし、「メジャー」から「カウント」をクリックします。
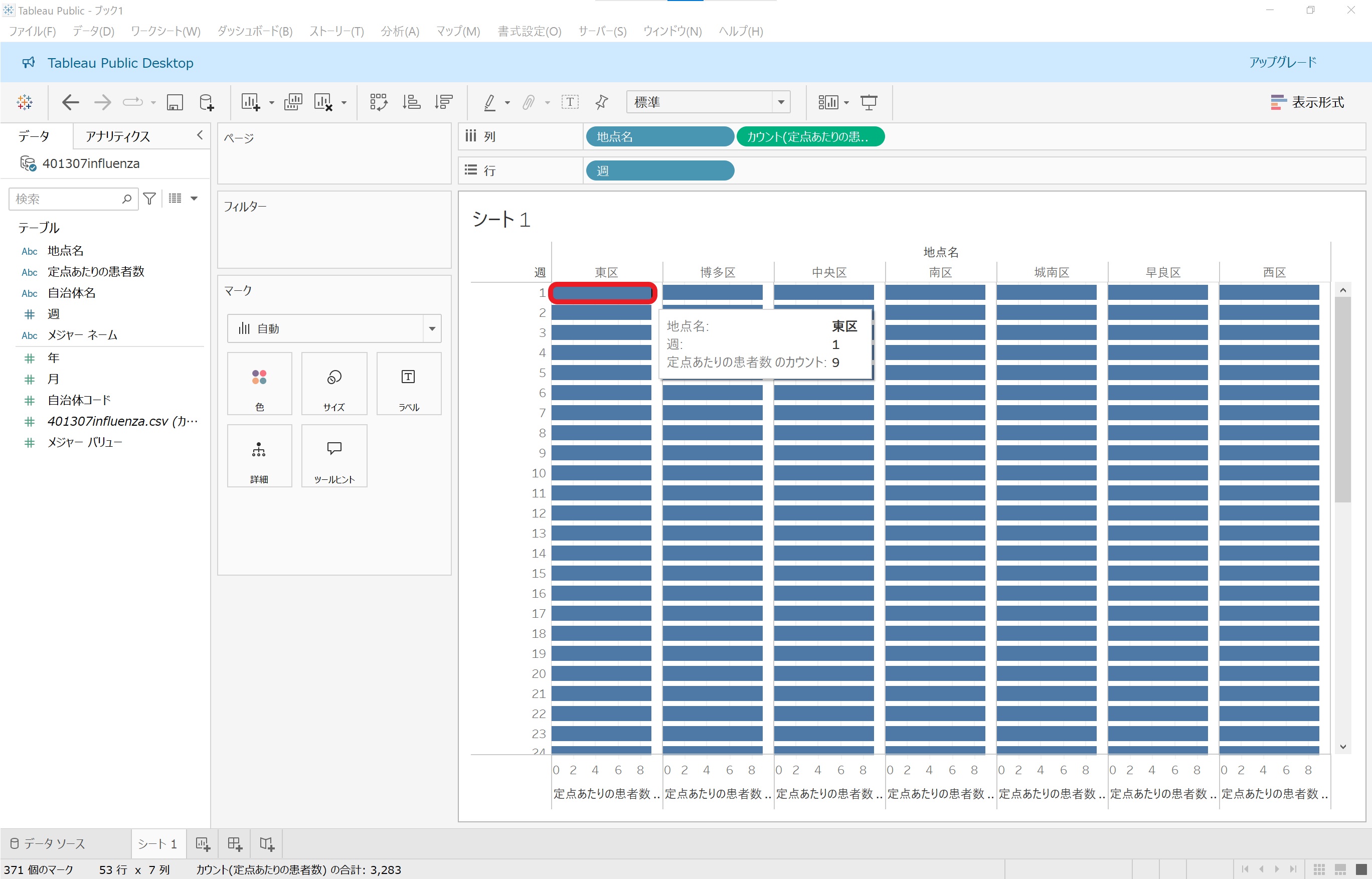
グラフっぽくはなりましたが、やっぱり「思ってたんと違う」感じに以下略。任意の場所(ここでは東区の第1週)にマウスを重ねると、集計された内容がホバーして表示されます。
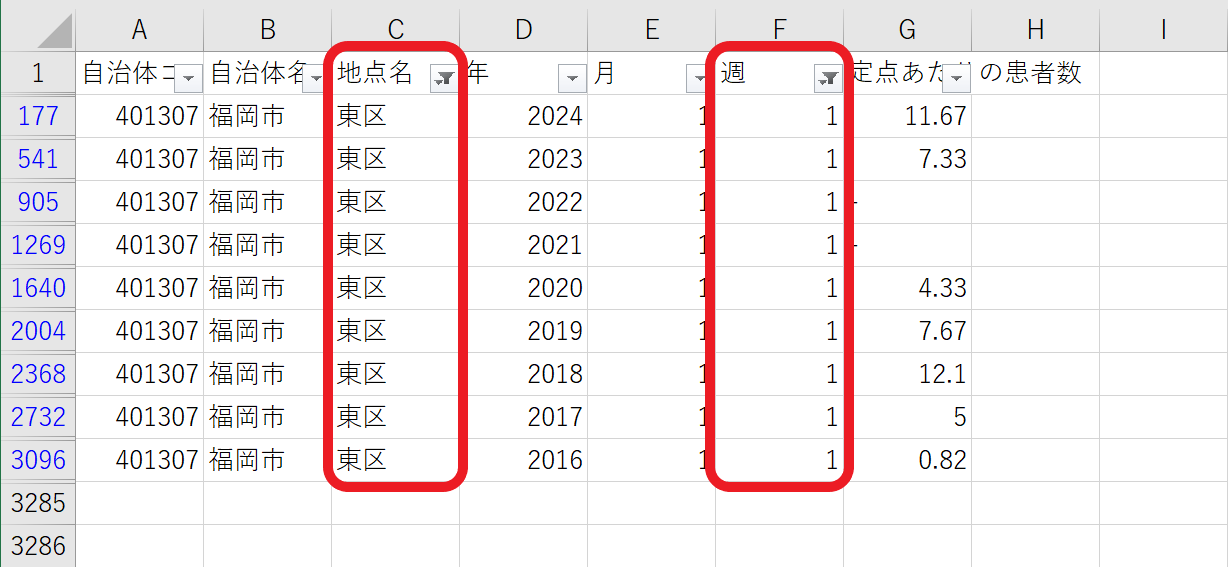
ここで、元のCSVのデータを「東区」AND「第1週」でフィルタリングしてみると、2016年~2024年のデータが9件あることがわかりました。
先ほどのホバー表示で「定点あたりの患者数 のカウント: 9」と表示されたのは、この9件のことを指していたのです。ここからの軌道修正はセクションをまたぎます。
フィールドのタイプは適切に設定する

「年」や「月」も「このワークブックではディメンション」の方がいいな……と思ったので、ここのタイミングでしれっと変換しています。
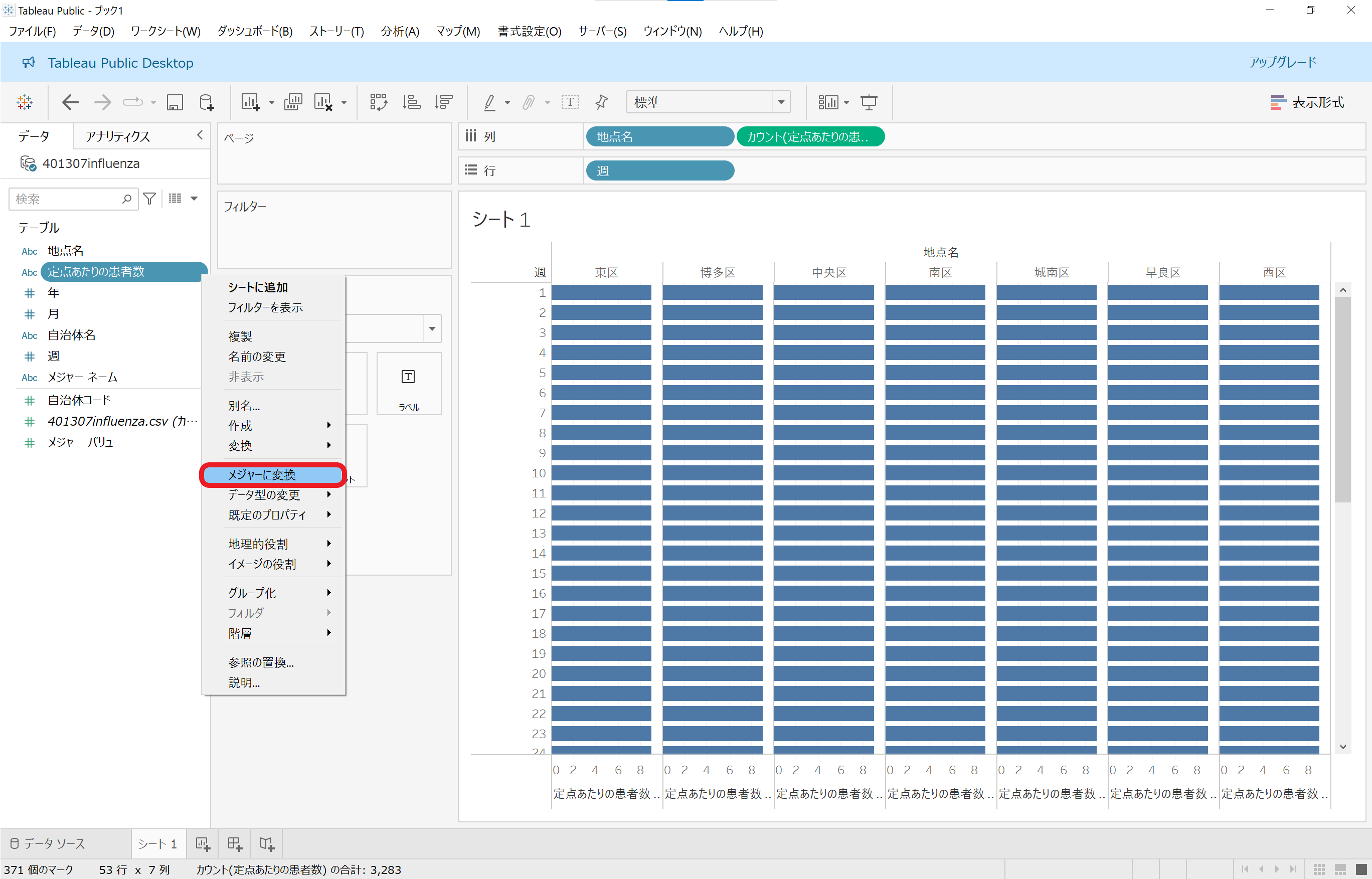
「定点あたりの患者数」はむしろメジャーだよねってことでこちらもしれっと変換(ver.2024.1.2でスクリーンショットを取ったときは、自動でメジャーに割り当てられていたのです)。
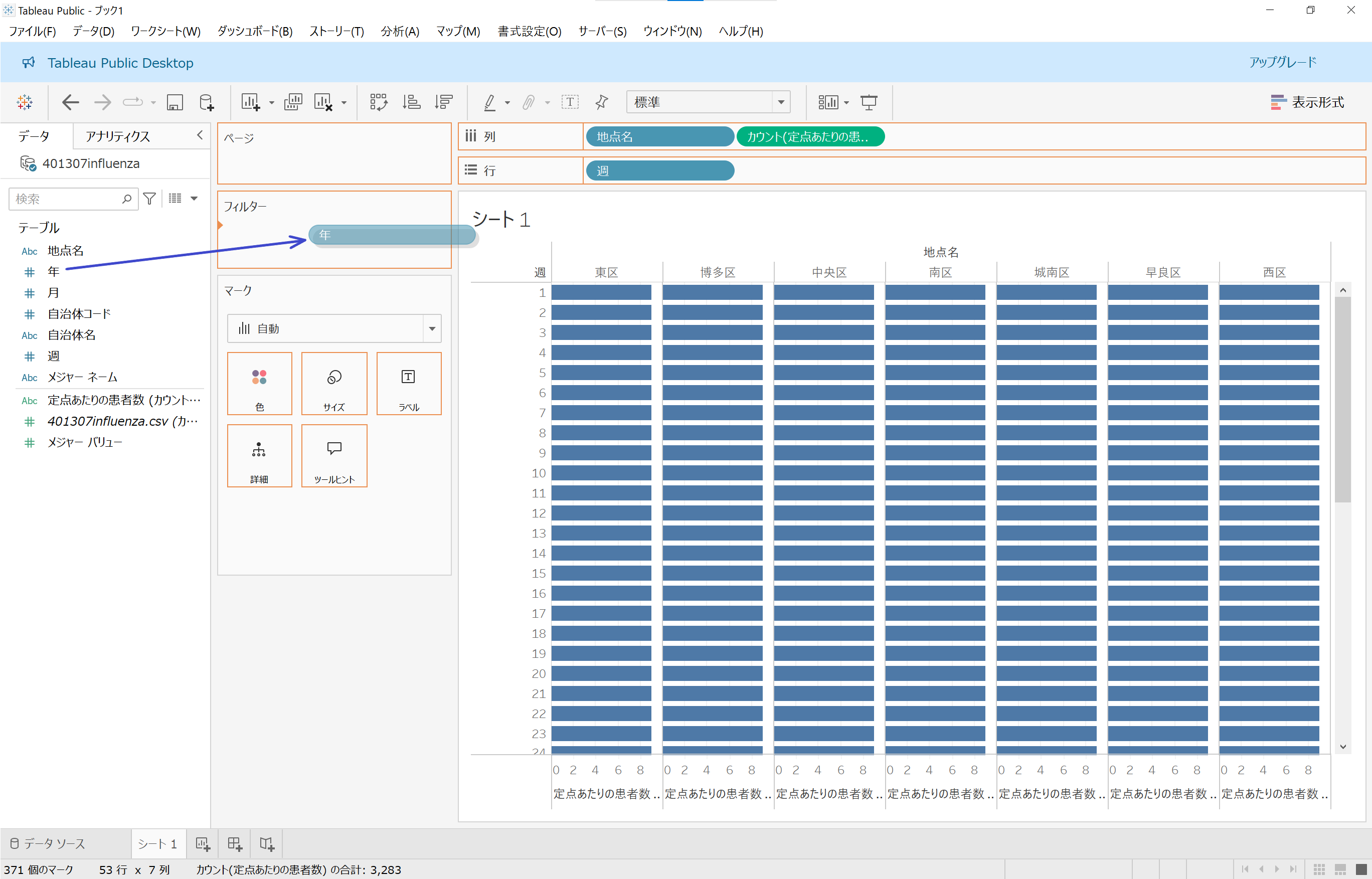
Tableauの場合は年ごとの同じ月や週の時系列による変化など、多彩な分析することもできますが、今回ははじめてのワークブック作成なので、シンプルに「1年間における各週の推移」を分析するようにしましょう。シェルフ内の「フィルター」部分に「年」フィールドをドラッグ&ドロップします。
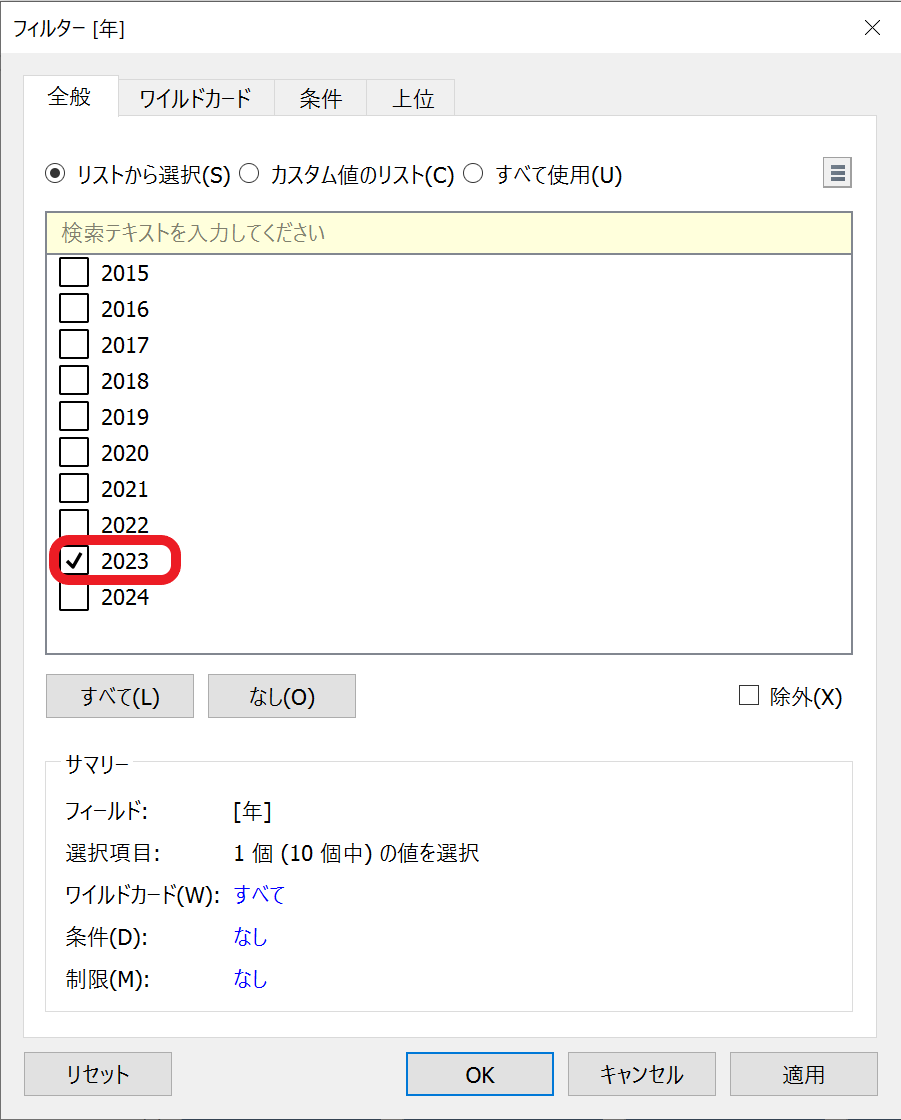
2024年のデータはまだ出揃っていないため、今回は「2023」にチェックを入れて「OK」をクリックします。
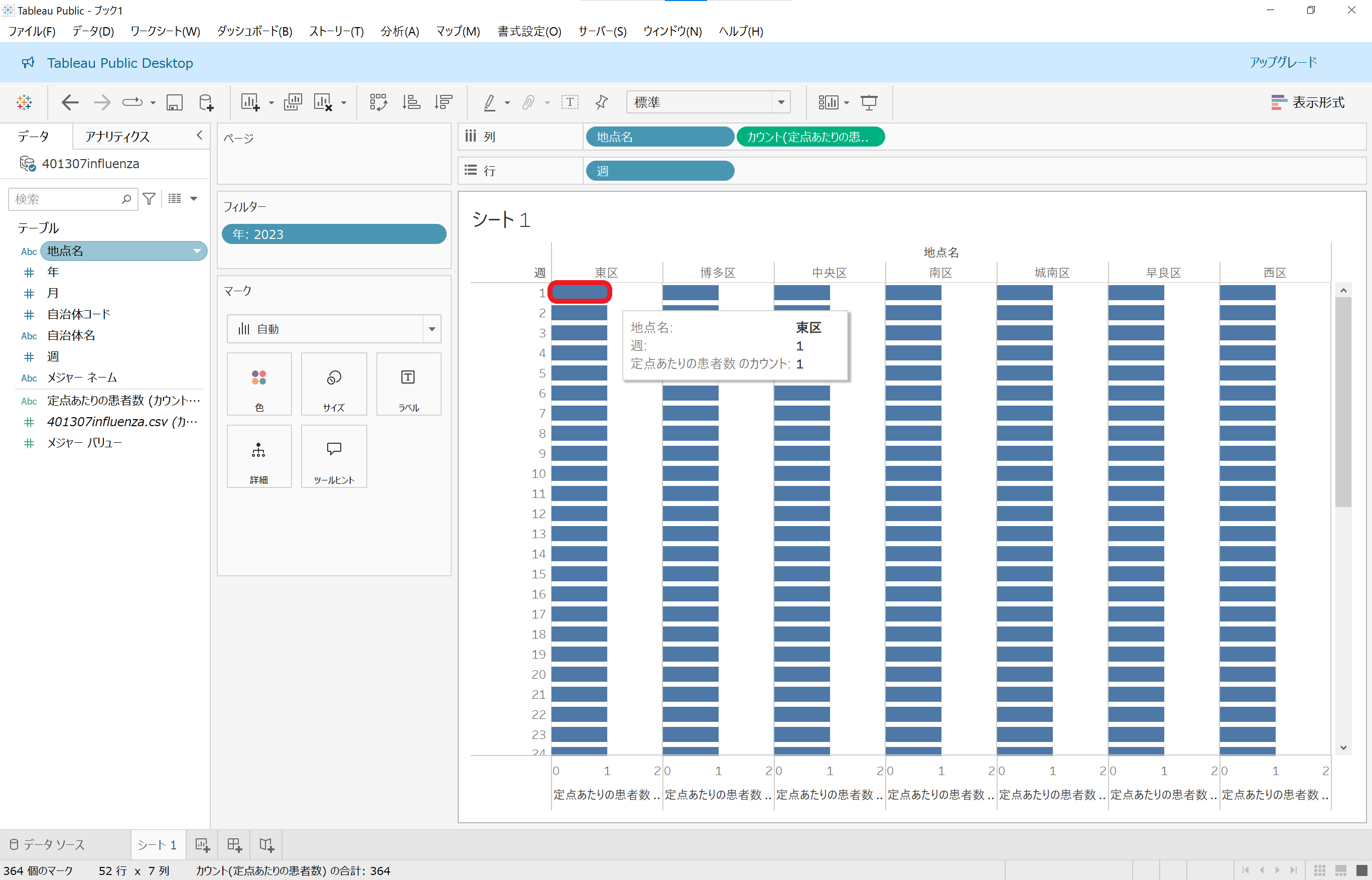
それでもやっぱり「思ってたんと違う」略。東区の第1週にマウスを重ねると、ホバー表示では「定点あたりの患者数 のカウント: 1」というように絞り込まれてはいますが、他の区も他の週も同様に全く同じ「1」のカウントが表示されています。
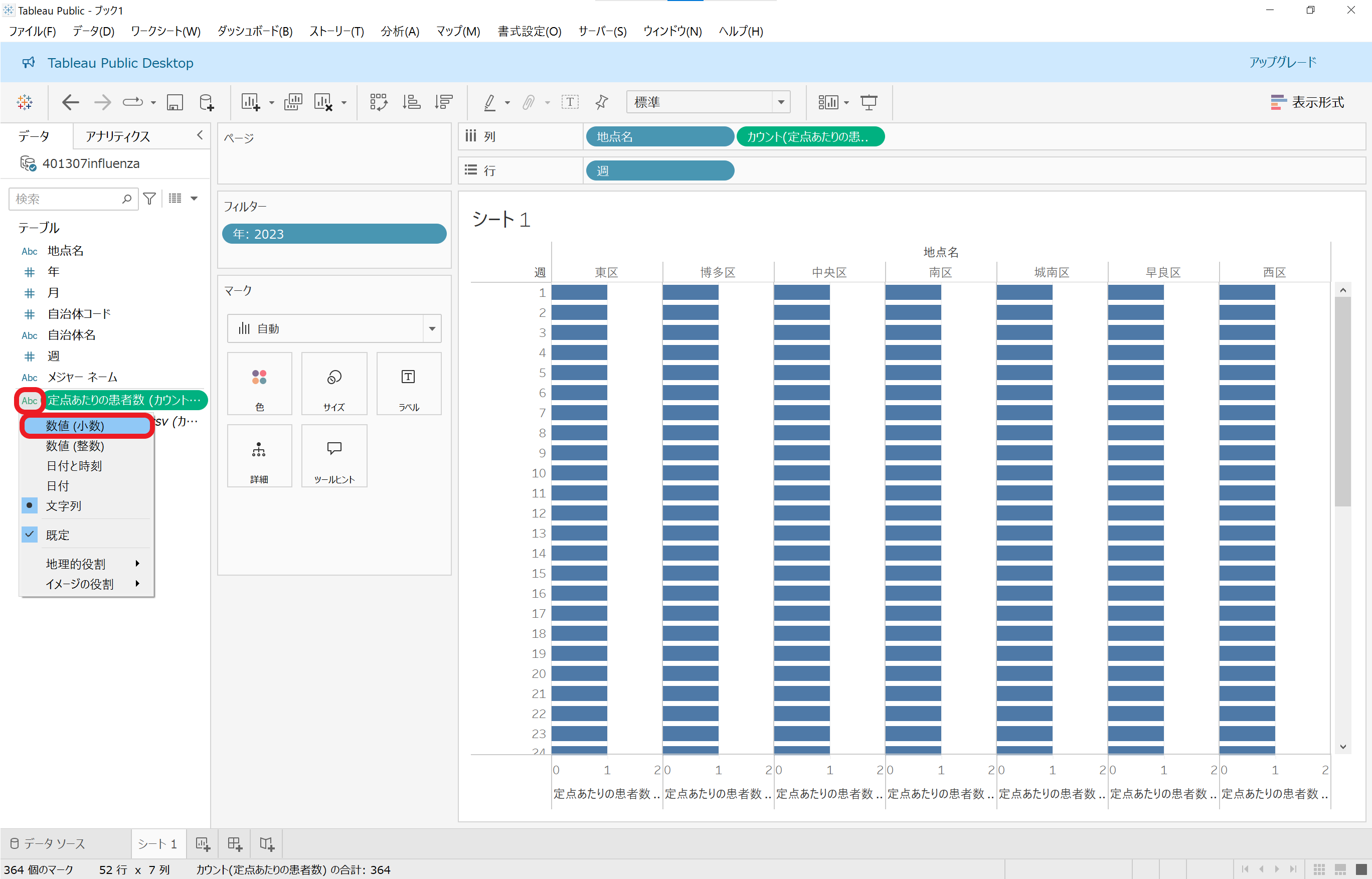
今までスルーしていた(気が付かなかったともいう)のですが、実は「定点あたりの患者数」フィールドのタイプが「Abc(文字列)」になっていたようです。
「定点あたりの患者数」は、元データでは小数点以下の値もありますので、「数値(小数)」に設定しなおします。
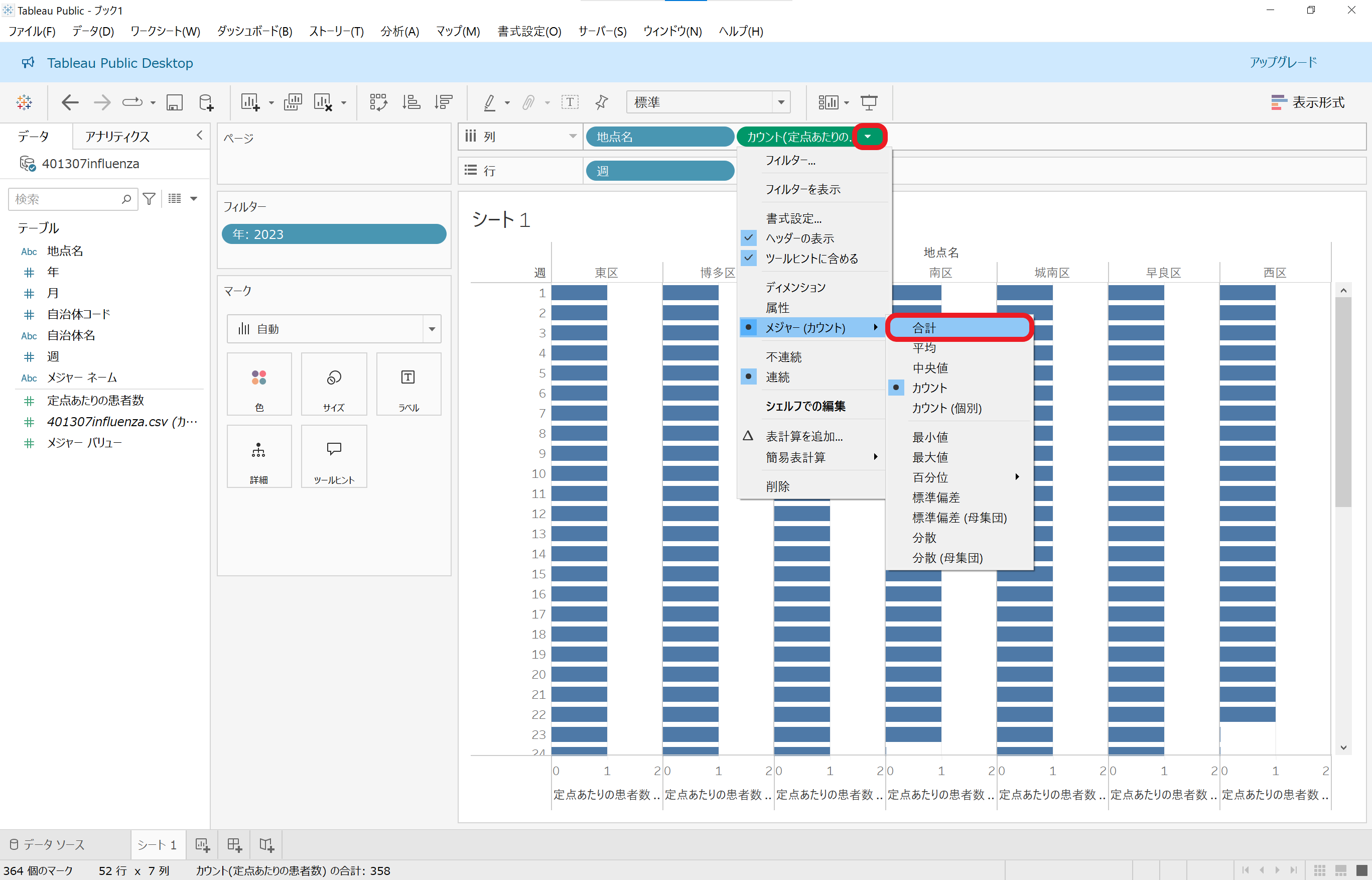
前のセクションの手順と同じように「定点あたりの患者数」のラベルの右端の▽をクリックし、「メジャー(カウント)」を選んでみると、タイプが文字列だった際には「最小値」「最大値」「カウント」「カウント(個別)」の4つしかなかった選択肢が10個以上に増えています。今回は「合計」をクリックします。
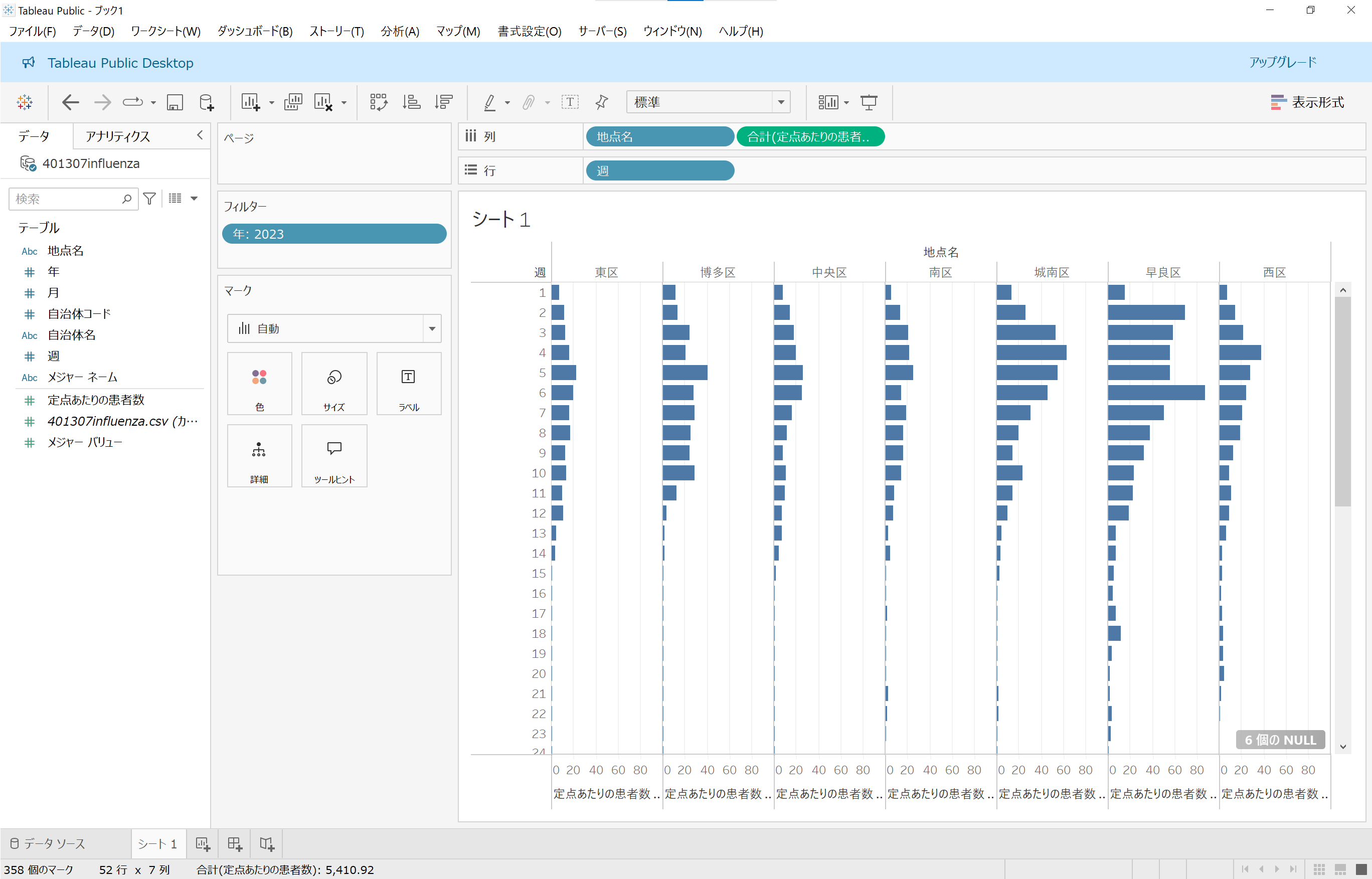
どの区も第1週~第12週(1月~3月)の感染者数が多く、第13週以降に減少していることが視覚化されました!(早良区はちょっと違う傾向のようですが……)
ビュー内のデータを並び替える
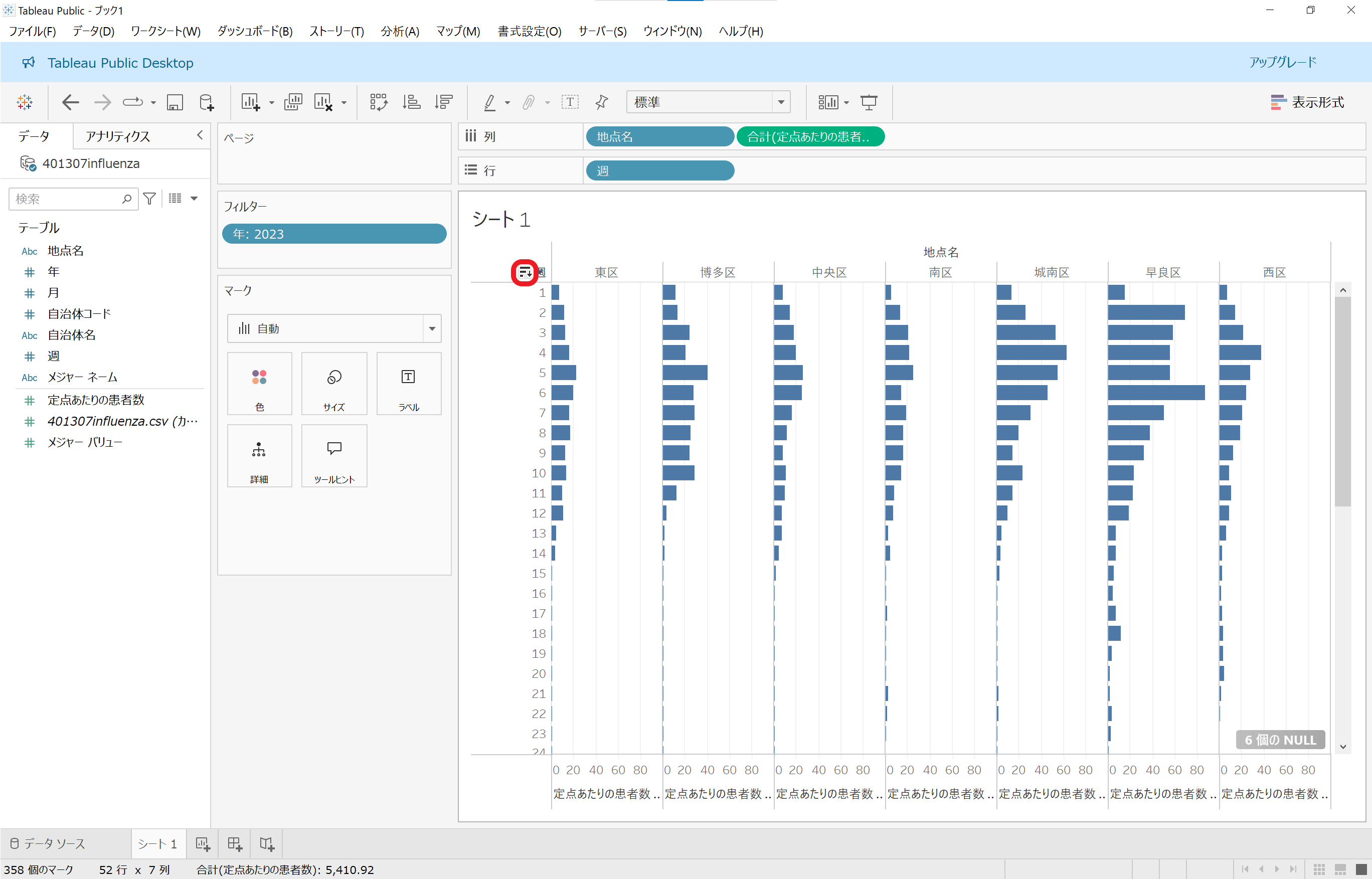
感染者数の推移を知りたいので、週数は降順にしたいところですね。そういうときは、ビュー内にある「週」のところにマウスを重ねると出てくるマークをクリックして、並び順を昇順から降順に変更できます。
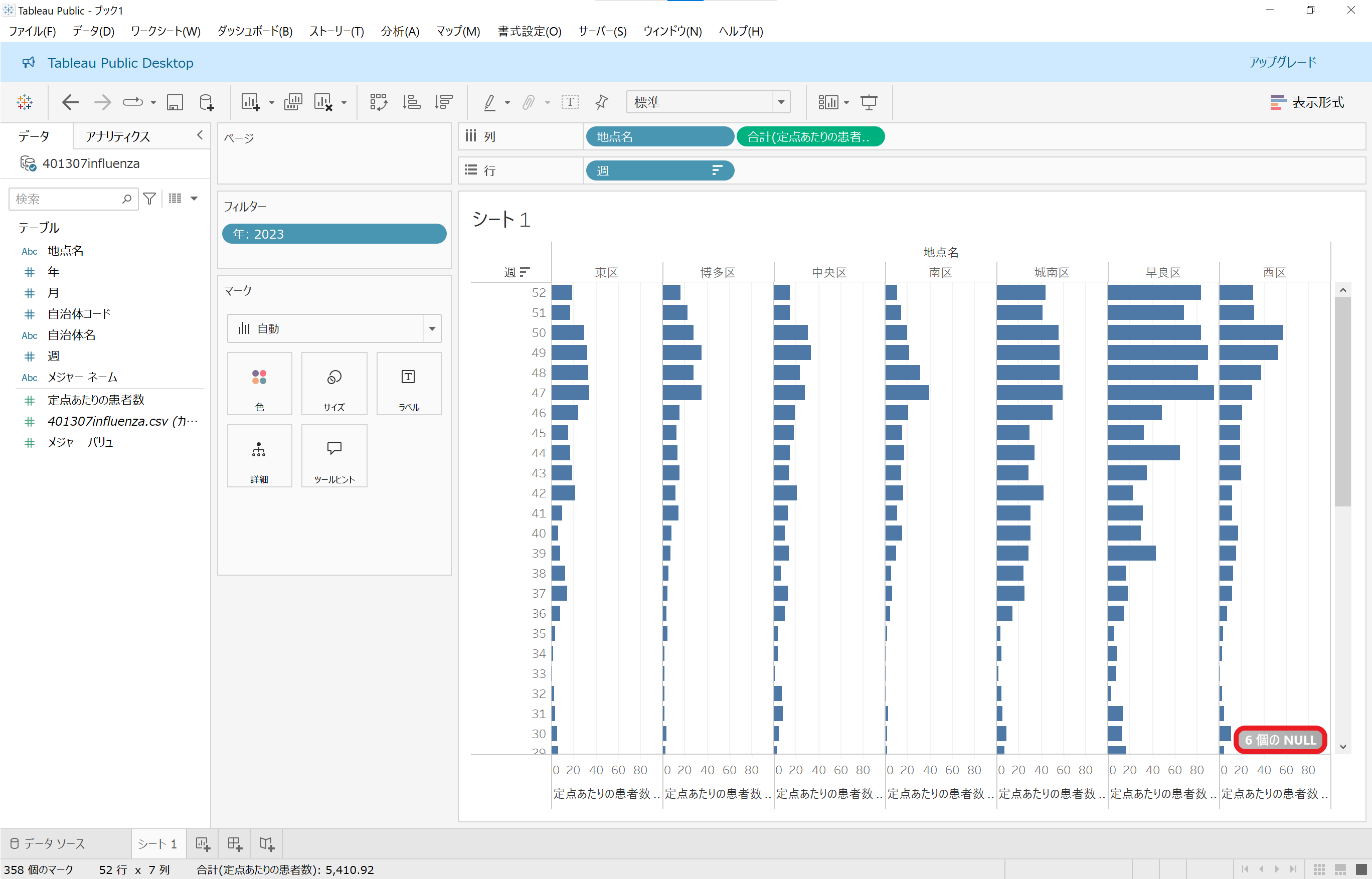
夏の間は減少していた感染者数が、どの区も第36週(9月)くらいからだんだん増加していることがわかります。
NULL値の処理
先ほどの画像の右下の「6個のNULL」という表示が気になりますが、これは元のCSVにそもそも「定点あたりの患者数」データが存在しない行がいくつかあるためです。
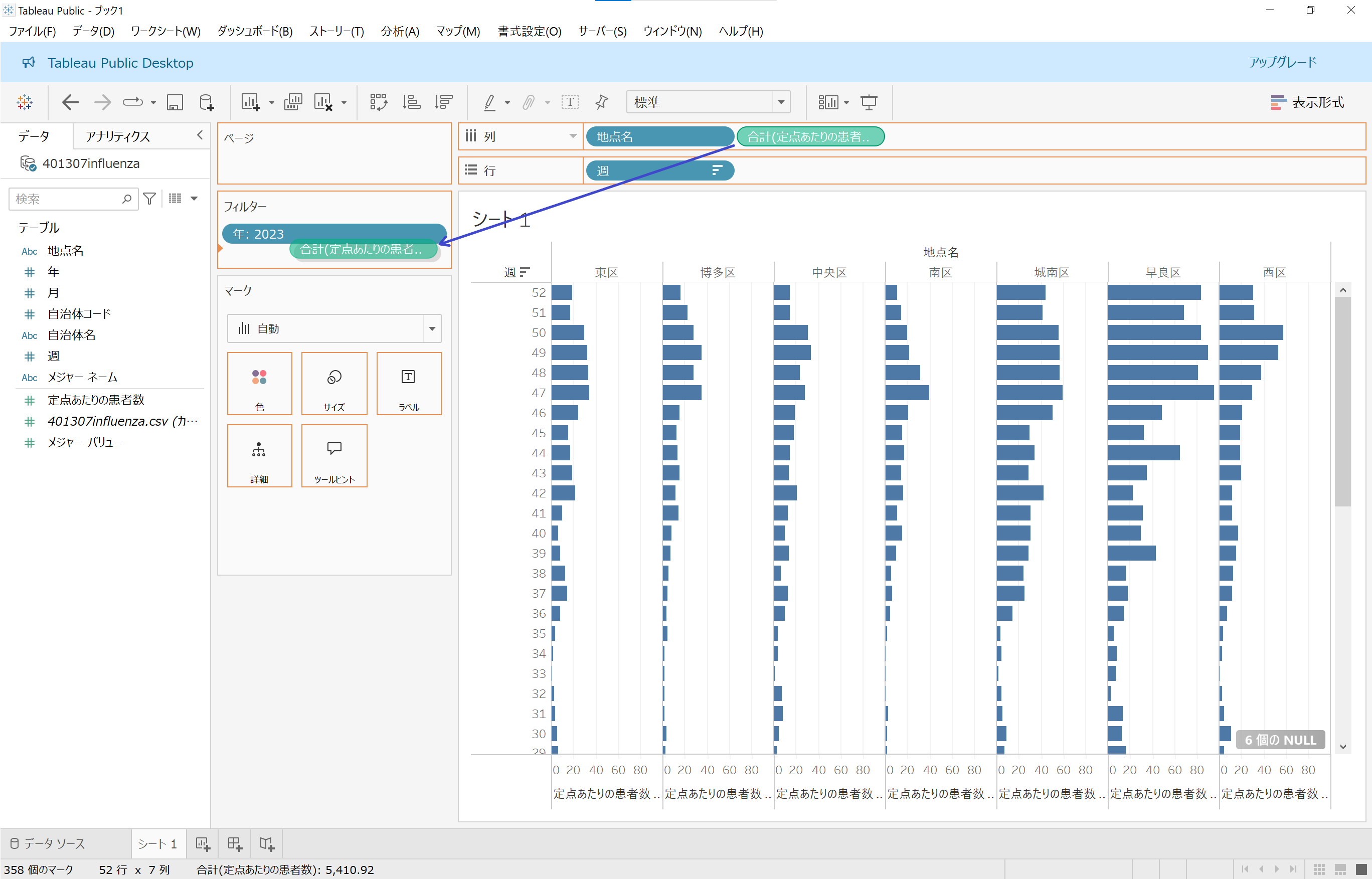
「○個のNULL」の対処方法はいくつかありますが、今回は「年」の絞り込みと同じようにフィルターで対処します。シェルフの「列」部分にある「合計(定点あたりの患者数)」を「フィルター」部分にドラッグ&ドロップします。
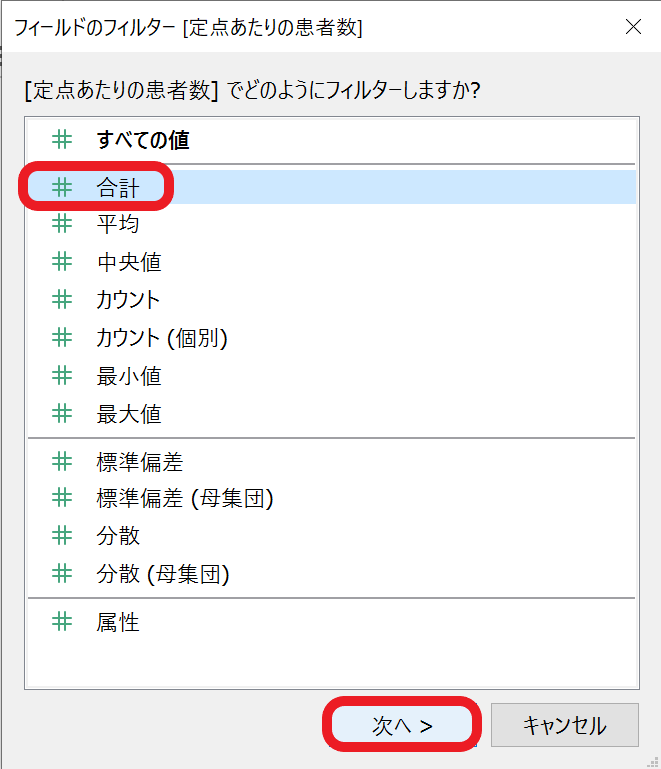
すでに定点あたりの患者数の「合計」でグラフを表示しているので、「合計」を選択して「次へ」をクリックします。
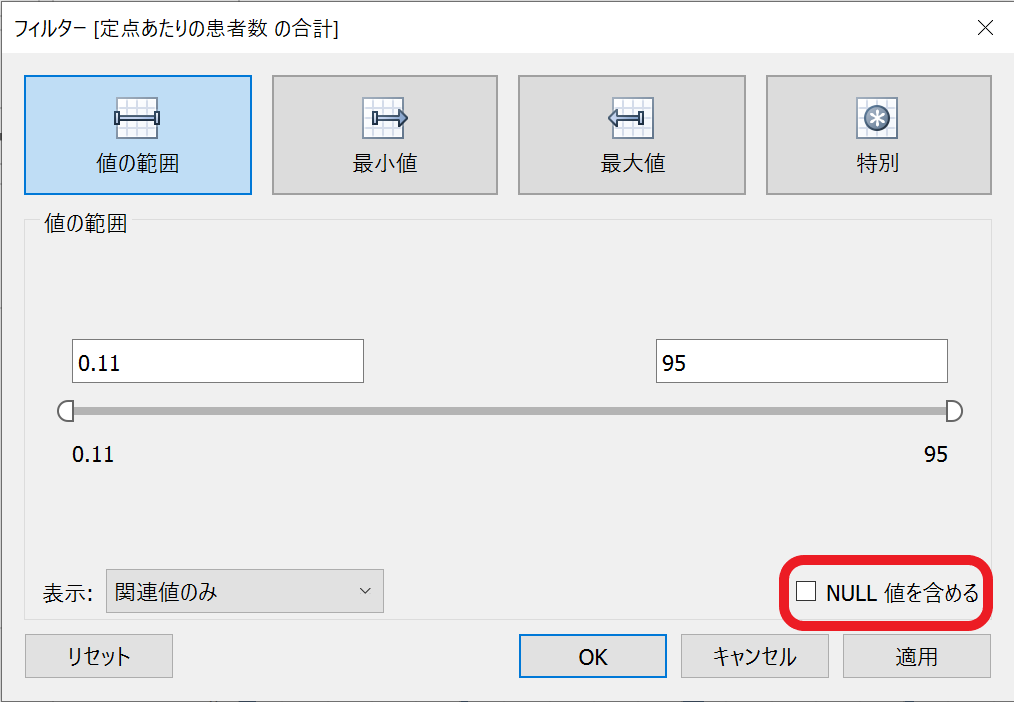
ここで「NULL値を含める」のチェックを入れないようにすることで、NULL値が含まれるレコードを、分析結果に含めないようにすることができます。
おっと、フィルターに「合計(定点あたりの患者数)」を持って行ってしまったので「列」からいなくなってしまいました。
もう一度「定点あたりの患者数」を「列」にドラッグ&ドロップし、「メジャー」から「合計」をクリックします。
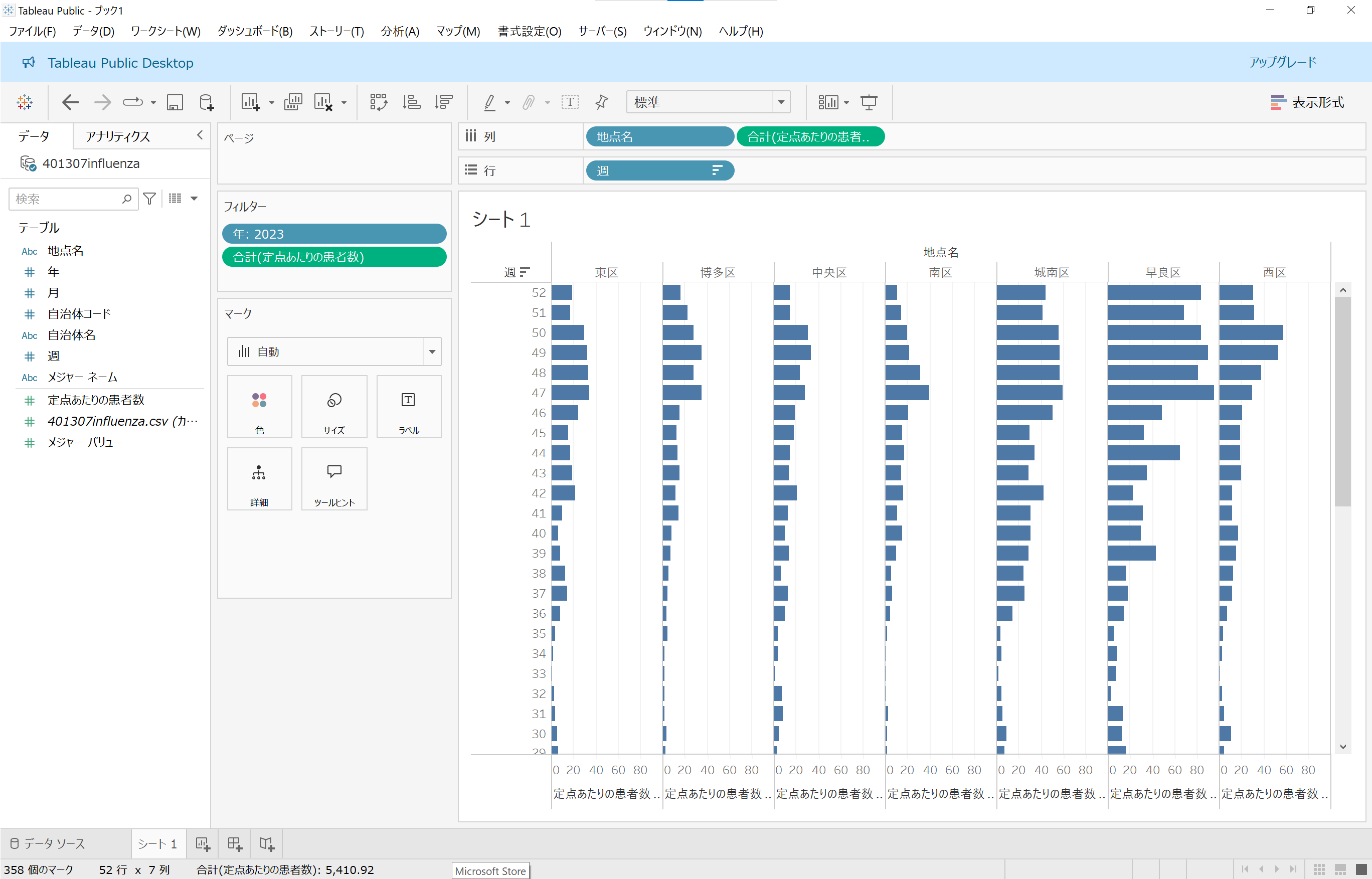
「○個のNULL」が消えたグラフができあがりました!
グラフとしてはいったんできあがりましたが、もう少し見せ方を工夫したいところですね。
その解説はvol.4で行います。

コメント